This diagram describes the architecture of what we'll be building. It's from Neo4j, creators of the graph database with the vector index we're using for this project. It shows how the system's components are arranged. You can learn more about it from their blog.
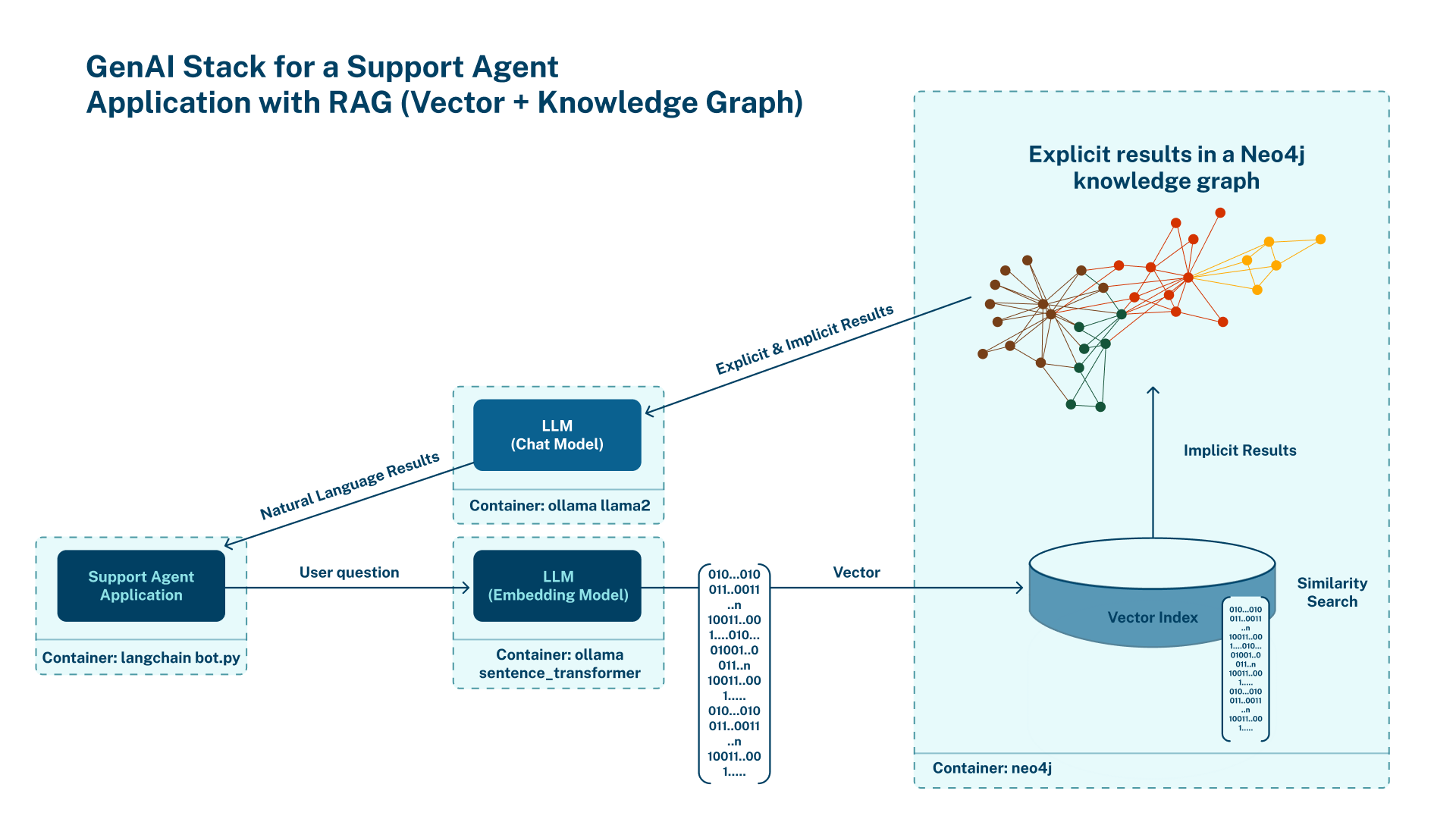
I won't bore you with many details just yet. Here's a brief description of what we're building so we can just jump right in and get started. I've added a ton of links so you can dive deeper on the concepts later.
As you can see from the architecture shown above we'll be using two pre-trained LLMs. The all-MiniLM-L6-v2 from the Sentence Transformers framework will handle encoding the document and your questions into vector embeddings and Meta's brand new SOTA model, Llama3.2:1b-instruct-q6_K is a 6 Bit quantized model. You can learn more about quantization here.
Using a quantized model makes chat inference faster with decent accuracy on CPUs. Neo4j's Vector Index + Graph Database will handle vector similarity search and storage of the PDF document's vector embedding (representations) so Llama3 (or any other LLM you chose) can read it and talk to you about it.
Finally, we'll be using two Ollama instances running in separate containers. One instance will handle downloading and orchestrating the models in your environment. The other Ollama instance will take care of your LangChain processed text & PDF file input with the API requests from your Streamlit UI for transformation and storage in the database using the all-MiniLM-L6-v2 LLM. It will also handle transformation of the LLM's vector embeddings output and Retrival of your PDF document's relative segments, putting the "R" in (RAG). Transforming it into Natural language we can understand using Llama3.2:1b-instruct-q6_K.
This diagram describes the structure of the containers we'll be using.

Docker's team collaborated with the team at Neo4j and created the guide which inspired me to write this. See the guide hosted by Docker for more details about the components we'll be using. I forked the repo and added some small tweaks to make it a bit more CPU friendly. More on this later.
With all that out the way, lets begin!
To get started fork or clone the repo from the GitHub link above, or open your terminal and run this git clone https://github.com/hamilton-labs/docker-genai-sample.git. Then checkout the "h-labs-og" branch with git checkout h-labs-og or "switch" to it with git switch h-labs-og. You could "refresh" your new repo with a git pull or do that later on to get the latest changes.
Hop into the repo's folder by running cd docker-genai-sample/ Docker Desktop is required to run the docker init command and generate the files seen here. If you want the full experience of Docker's guide, install Docker Desktop if you need it and proceed. If you already have the Docker Engine installed then you could switch contexts to run the init command after installing Docker Desktop and switch back to the Docker Engine when you're ready.
When running in CPU mode, Ollama checks for a compatible instruction set of APIs to communicate with your CPU.
Here's a list of the ones it checks for:
Dynamic LLM libraries [rocm_v6 cpu cpu_avx cpu_avx2 cuda_v11 rocm_v5]Check if your CPU has the AVX instruction set with one of these commands:
(Linux)
grep avx /proc/cpuinfo | head -1v
(Linux)
cat /proc/cpuinfo| grep flags | head -1v
(On Mac)
sysctl -a | grep machdep.cpu.features | grep AVXCopy the env.demo file to .env with:
cp env.demo .envEdit your .env file to fit the appropriate AXV set and other settings you need for your environment.
(example)
#*******************************
# LLM and Embedding Model
#*******************************
LLM=llama3.2:1b-instruct-q6_K # Downloads the quantized LLM (1.0GB)
EMBEDDING_MODEL=sentence-transformers:all-MiniLM-L6-v2
#*******************************
# Ollama
#*******************************
OLLAMA_BASE_URL=http://ollama:11434
HIP_VISIBLE_DEVICES=-1
OLLAMA_INTEL_GPU=1
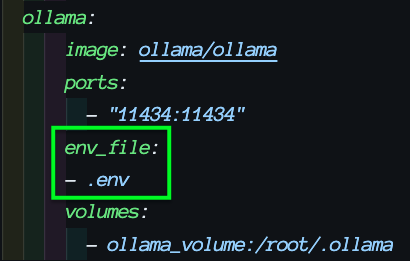
OLLAMA_LLM_LIBRARY=cpu_avxMake sure to add your .env file to the appropriate sections in your compose.yaml file:
Now run:
docker compose up --build or docker-compose up --build
We'll have 4 containers running
docker-genai-sample-server-1 // streamlit.io server
docker-genai-sample-ollama-1 // ollama server
docker-genai-sample-ollama-pull-1 // ollama (downloader) server
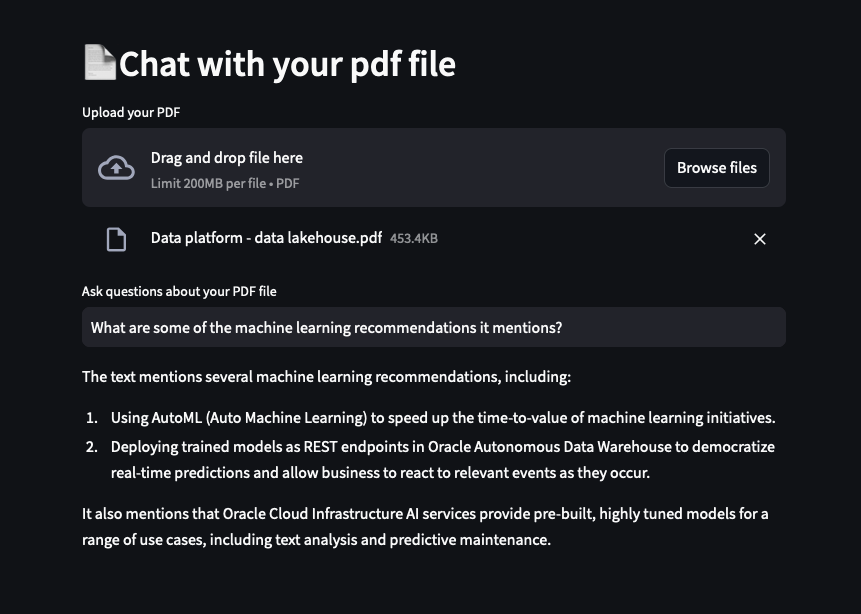
docker-genai-sample-database-1 // neo4j.com The Graph DatabaseIf all went well you should have a Streamlit UI running at 127.0.0.1:8000 a.k.a. (localhost:8000).
Here's a screenshot from one of my tests.
If you're like me you'd like to know what's going on and want to monitor the logs. You can monitor the logs by opening a new terminal window and running this:
docker logs -f docker-genai-sample-ollama-1( You can do this for each container in separate windows )
If you get errors, read the error, try what its suggesting, Google it, or try re-running docker compose up --build. If none of that works copy and paste it into a new issue and/or discussion and I would be happy to discuss it with you.
docker compose downUse this to tear everything down and delete the containers if you don't want them any more.
Or just stop the containers and hold on to them with:
docker stop <container name>This tutorial is really for CPU users. If you have a GPU available then see the prerequisites here.
Model developers could use this setup to import, quantize and test custom models locally in an application setting with a few adjustments.
BTW, please count this as me fulfiling one of my promises to you of presenting a GPT app.
I'd like to send a huge thank you to Docker & Neo4j for releasing their guide which inspired me!
Well that's it for now. I hope this all worked out for you! If so feel free to hit me up or shout me out over on Linkedin or Twitter!
Enjoy!